省流:Canary爆破,顺便复习了一下Linux socket API,还知道了IDA View下右键数值常量可以查找对应的枚举名(前提是要指知道枚举名的开头)(比如AF_INET、SOCK_STREAM等)。
【Network#0x00】自顶向下笔记#Ch1
1.1 What is Internet
软硬件实现角度:各种各样的终端设备 end system通过线路和 packet switch 链接在一起,中间有一张大网——因特网核心。终端设备通过 ISP(Internet Service Provider)与这张大网连接在一起,ISP 之间也互相连接。
在 end system、packet switch 等网络设备上进行传输的,是遵守协议 Protocal的数据包,作为所有设备间的约定来规范网络上的数据形式。这些规则大部分由 IETF 制定,称为 RFCs,也有由 IEEE 等组织指定的标准。
功能角度:在终端的眼中,网络是提供服务和应用的基础设施。终端可以借助网络接口来使用或构建分布式应用。
1.2 The Network Edge
在网络的边缘,有各式各样的网络的终端设备,比如 PC、服务器、移动设备、以及越来越多的各式智能联网设备(The Internet Of Things),它们都可以被称为 host。
不过很多时候,这些 host 有着 client 或者 server 的差异。
1.2.1 Access Internet
接入网络 access internet 是指从终端设备到达第一个 router(edge router)的这一段网络,通常是 ISP 假设的。接入网络有很多物理实现:
Home Access
DSL(Digital subscriber line):在国内也叫做 ADSL(asymmetric 非对称),是一种复用电话线作为网络传输的技术。数字信号经过 DSL Modem 转换为高频声音信号,和相对低频的电话信号一起传输。在用户家里,有个 Splitter 会把两种信号分隔开或组合起来;在 ISA 那里(电话服务提供商兼 ISA)的 Central Office,也有称为 DSLAM 的设备来做这项工作。
Cable Internet Access:使用同轴线和光纤混合连接,是一种复用有线电视线的技术。数字信号经过 cable modem 转换为模拟信号,在 HFC hybrid fiber-coaxial 线路上传播,在 CMTS Cable modem termination systems 上再次转换为数字信号并进入网络。
数以百计甚至千计的家庭通过同轴线连到 Fiber node,再通过光纤连到 CMTS。
FTTH(Fiber to the home):光纤入户,纯粹的网络连接。在用户家里,数字信号经过 ONT 处理转换为光信号,很多户的信号在一个 Optical splitter 处汇总(分隔)后通过一条光纤连接到 CO 的 OLT,接入网络。
除了上面三种方式,还有面向偏远地区的卫星接入方式,以及和 DSL 技术一样但速度慢得多的拨号上网。
Access in Enterprise (and the Home): Ethernet and WiFi
企业内部会使用局域网 LAN Local Area Network,而以太网 Ethernet 是最广泛的局域网实现。
无线局域网 Wireless LAN 通常使用 IEEE802.11,也叫做 WiFi 技术。典型的家庭会使用 WLAN 和 Internet 的结合。
Wide-Area Wireless Access
广域无线接入,如 5G,基于分布于各处的基站来提供服务。
1.2.2 Physical Media
许多房子在建设的时候就会同时埋好铜线、同轴线、光纤,这样以后更换 ISP 接入方法的时候就不用重新装(线缆的价格比网络设备便宜得多)。
1.3 The Network Core
网络核心是及其复杂的,由包交换机(主要是 router 和 link-layer switch 两种)互相连接而成。
1.3.1 Packet Switching
包交换机有以下的特点:
- Store-and-Forward Transmission:接受完一个完整的数据包之后,再开始传输。这会使数据包在每个包交换器那边产生 L/R 的延迟,式中 L 表示数据包大小、R 表示线路的比特传输速度。
- Queuing Delay:对每个出口,包交换器都有个缓冲区,等待发送的数据包会在这里排队。等候的实践就叫做排队延迟。
- Packet Loss:超过缓冲区的数据包,包交换器会直接丢弃,造成丢包。这里体现了网络设计的 Best Effort 原则。
- Forwarding Table and Routing Protocals:路由器根据每个数据包的目的 IP 信息,查询 Forwarding Table 来决定向哪里转发数据包。Forwarding table 根据 routing protocal 路由协议来进行维护。
1.3.2 Circuit Switching
当今的 Internet,是一个分组交换的网络。电路交换在历史上曾是网络实现的有力的竞争者,但最后还是不敌分组交换技术。
电路交换的最大特点就是为两端的用户提供持续稳定的连接,不允许其他的用户借用其资源。
电路交换有两种实现方式,重点在于如何复用一根线缆来支持多个连接:
- FDM Frequency-division Multiplexing:每个连接独享一小段频谱;
- TDM Time-division Multiplexing:将整个时间轴分成一个个 Frame,有 N 个连接就把 Frame 切成 N 段 Slot,这样每个连接都会在每 Frame 时间段中占用线路 Slot 时间。
电路交换的最大缺陷在于:无法很好地利用起用户静默时段的线路资源(silent period);在用户数量大的时候性能比包交换差。具体例子参考书 p30.
1.3.3 A Network of Networks
网络核心的复杂性并非是最初设计带来的复杂性,而是不断发展而带来的复杂性。
最简单的网络显然是一个 ISP 统一全世界,所有终端都连接到这个 Global ISP 上。
但是这就造成了垄断,不利于市场的发展,于是由于市场因素有了多个竞争的 ISP。
国际性的 ISP 往往无法深入当地,因此很多地方有了本地的 Local ISP,比如上海电信。
国际性和本地的 ISP 形成了 Provider ISP 和 Client ISP 的关系,Provider ISP 会建立 PoP(Points of presence)以供 client ISP 接入。
为了防止有的连接从本地转到国际再转回本地,本地 ISP 之间会建立 IXP(Internet Exchange Point)来互相连接,加速网络。
一些大厂(Content Provider)为了给自己的服务加速,也会建立全球的网络,并连接到 tier1 ISP、IXP、access ISP 等处。
1.4 Delay, Loss, and Throughput in Packet-Switched Network
刚刚提到这是包交换器的三大特点(缺点),下面是对于它们的详细分析。
1.4.1 Overview of Delay in Packet-Switched Networks
考虑数据包在一个包交换器那边的延迟,可以分为四种:
- nodal processing delay:包交换器中的程序处理数据包并计算出其转发口所需要的时间,取决于路由器本身的计算性能。
- queuing delay:数据包在出口缓冲区中排队的时间,比较难以计算,取决于实际网络交通情况。
- transmission delay:数据包被装载到线路上,或者被完整接受所需要的时间(这两段时间是相同的)公式为 $L/R$.
- propagation delay:数据包在线路上传输的时间,由于所有的线缆信号传输速度都是光速量级($210^8m/s$ ~ $310^8m/s$),通常可以忽略这一延迟。
计算公式为:$d_{nodel}=d_{proc}+d_{queue}+d_{trans}+d_{prop}$
注意 transmission delay 和 propagation delay 的区别。transmission delay 取决于传输技术所设计的比特速率(用多长的信息来表示一个 bit?),而 propagation delay 取决于线缆本身的材料。
1.4.2 Queuing Delay and Packet Loss
计算排队延时用到了一个指标 $La/R$,式中 L 表示平均包长度,a 表示包接受速率(包每秒),R 表示比特输出速率(比特每秒)。
平均的排队延时和 $La/R$ 之间成正相关,且后者越大斜率越大,到 $La/R$ 接近 1 时,平均的排队延时将会趋向无穷大。(根据 P40 的图看出……)
由于 La 和 R 其实都是设计者可以预计并控制的数字,设计者应该小心地设计网络设备来防止其比值过大导致排队甚至丢包。
1.4.3 End-to-End Delay
从一个终端到另一个终端,到底经过多少延迟?可以用这个公式来估算:
$d_{end-end}=N(d_{proc}+d_{trans}+d_{prop})$
为了实测延迟,可以使用 traceroute 工具,它会向路径上的每个节点发送并接受一个数据包,从而拿到到达每个节点的延迟。有趣的是,有时后面的节点反而延迟比前面的节点要小,这多是由于不可估算的排队延迟所造成的。
1.4.4 Throughout in Computer Networks
在下载大文件时,比起延迟我们更关心的是吞吐量,也就是下载软件显示的 Mb/s。
实际上,ISP 假设的核心网络是 over-provisioned 的,有着极高速的链路,很少会产生拥堵。
吞吐量主要受到两方面的限制:
- 整个链路中最慢的线路(一般是接入网络)
- Traffic 情况,即使是快速线路,在流量大的时候也会产生拥堵
1.5 Protocol Layers and Their Service Model
1.5.1 Layered Architecture
整个计算机网络系统是复杂的,但通过将系统划分层次的结构化方法,可以将局部复杂度大大降低的同时也使允许的总体复杂度增加,这就是网络的层次结构。
在网络的层次结构中,每一层都为其上的层提供一种服务(这叫做 Service Model),通过:
- 在本层内执行某些操作
- 使用其下一层所提供的服务
通过一层一层服务的叠加,便最终有了丰富多彩的各种互联网应用。
互联网从设计时就采用这样的结构化设计,好处在于概念清晰、可以允许不同的实现(更易优化);但也有人批评这种做法可能出现多个层次之间有重复工作降低效率,或者不利于某些跨层次的操作(如在应用层需要更低层的数据)。
具体来说,Internet 协议栈分为五层:
- Application Layer
- Transport Layer
- Network Layer
- Link Layer
- Physical Layer
每个协议都会在特定的层次上运行,类似于层次概念的实际实现,因此这个层次架构会被称为协议栈。
Application Layer
提供服务:取决于想象力
常见的协议:HTTP、SMTP、FTP、DNS
应用层数据包被称为 message。
Transport Layer
提供服务:可靠、有流量控制机制的数据传输(TCP)或不可靠的传输(UDP)
常见的协议:TCP、UDP
传输层数据包被称为 segment。
Network Layer
提供服务:将数据包从一个主机发往另一个主机
常见的协议:IP(only one)、routing protocal(很多种)
传输层数据包被称为 datagram。
Link Layer
提供服务:将数据包从链路一端发往另一端
常见的协议:Ethernet、WiFi
传输层数据包被称为 frame。
Physical Layer
提供服务:将 bit 从链路一端发往另一端
常见的协议:铜线、同轴线、光纤
取决于介质,由 modem 使用。
OSI 7 层模型最早提出,不过那时候还没有实现 Internet,所以其实是纯理论依据的模型。不过教学时经常采用这个模型。
至于我们要用哪个模型?OSI 多出来的两层有没有用?这取决于应用的开发者用不用这两层功能。
1.5.2 Encapsulation
考虑上层与下层的关系:上层的数据包作为 payload,下层协议将自己的信息作为 header 附加到数据包上,从而完成对上层数据包的封装,成为了本层的数据包。可以类比把信装到信封中。
因此一个任意层的数据包都由两个部分组成:header field 以及 payload field。
其中,payload field 或许又可以这样拆分为两个部分。
此外,某些层的封装并不是简单的往数据包上面叠加信息,比如传输层的 TCP 协议会将应用层的数据包拆分成很多个部分分别进行封装,从而把一个应用层 message 封装成多个传输层 segment。
1.6 Network Under Attack
网络的本质是多台计算机之间的数据交换,在远古时期,用计算机的都是友好的研究人员,他们不会想到网络需要有恶意者的假设。
然而现代,网络攻击可谓层出不穷。计算机网络方向的一个主要研究课题,就是设计防御攻击的方法,甚至设计出对攻击免疫的协议。
带有恶意的黑客可以通过以下几种方式对网络进行攻击:
- 利用网络来传输恶意软件(malware),如利用用户不警惕心的 Virus,或者利用计算机系统漏洞的 Worm。
- 攻击服务器和网络基础设施,来让网络瘫痪(Denial-of-Service)。可以分为三类:漏洞攻击、带宽攻击(流量攻击)、connection flooding。后两种往往会使用 Distributed DoS,借助 botnet 进行攻击。
- 数据包嗅探:互联网最容易的就是监听了……
- 伪造正常数据包、伪装正常的用户。黑客完全可以手动构造一个数据包,只要填入各个字段就可以了。伪造来源 IP 就是一种常见的手法。
【PoRE#0x00】欢迎来到逆向工程原理
为了在学校的高强度课程《逆向工程原理 Principles of Reverse Engineer》存活下来,站主决定开启一个系列笔记,并同步到博客上。
目标是将课程以及实验的要点以人话讲清楚,整理一些便于查询的cheatsheet,并尝试拓展学习一些有趣的内容,以便同学和自己参考。(如果有同学看的话(´_ゝ`))
本期作为第0期,主要记录课程的基础设施使用方法。
【Pwn#0x0A】pwnable.tw tcache_tear writeup
完全自己做出来的一个堆题,算是入门堆利用了吧哈哈。
程序分析
GLIBC 2.27 64bits,关闭了 PIE。
菜单题,提供了 alloc、free、info、exit 四个功能。
- 通过 alloc,用户可以自由申请小于 0xff(不含 chunk header)大小的区块并向其中填入 size-0x16 个任意字符(奇怪的限制)。整个程序只有一个放指针的槽位,是一个全局符号,记为gptr。
- 通过 free,用户可以释放全局符号 gptr 指向的空间。但程序使用局部变量作了限制,程序最多只能 free 8 次。漏洞:free 完没有清空指针
- 通过 info,用户可以用 write 打印全局符号 name 处的值。这个符号本没有名字,但程序一开始会让我们输入一个 name 存储在这个符号的位置,所以就叫他 name。
- 通过 exit,用户可以退出程序。
程序没有什么自带的后门函数,orw 的三个函数都不齐。
思路
结合分析可以看出,必须要泄露 libc 基址才能搞事情。所以需要在 2.27 的版本下,想办法绕过 tcache 让 chunk 进入 unsorted bin 来获取 libc 地址。
程序的唯一打印功能是打印固定地址处的内容,所以还需要用 house of spirit 的思想在 name 处构造假区块。
综上,攻击步骤有如下几步:
- 构造 fake chunk 头部
- 构造 fake chunk 尾部,保证通过 free 的检查
- 释放 fake chunk 进入 unsorted bin
- 使用 info 功能泄露 libc 基址
- 覆写
__free_hook为 one_gadget
具体实现
构造 fake chunk
为了完成 House of Spirit 攻击,我们需要精心构造 fake chunk。
首先,为了不被分进 fastbins,chunksize 需要>=0x90,这里就使用 0x90。
其次,为了不与别的 chunk 合并,首先低位的 chunk 通过 0x91 的 1 来解决;高位的 chunk 就需要再构造两个 fake chunk,如下图所示:
1 | ├──────┬──────┤ │ |
fake chunk 的头部可以程序开始的时候输入 Name 0x91 来完成。高位的两个 fake chunk 就需要使用 tcache dub 然后 poisoning 来完成了,代码如下:
1 | # fake chunk header |
泄露 libc
构造完了 fake chunk,我们需要通过释放它来达到目的。为此我们有两种方法:一种是覆写全局 gp 为 fake chunk 地址;另一种是 poisoning tcache 把 fake chunk 取出,这里我们随便地采用后者。
1 | # alloc fake chunk |
然后就可以释放并泄露 libc 基址了:
1 | # free fake chunk into unsorted bin |
覆写 hook
有了 libc 基址,再加上 tcache 的任意写能力,就可以把 hook 覆写为 one_gadget 来完成攻击。脚本如下:
1 | free_hook = libc_addr + libc.symbols["__free_hook"] |
完整脚本
1 | #!/usr/bin/python3 |
【Pwn#0x09】ZCTF 2016 note2
正在学习Unlink - CTF wiki,参考上面的方法自己打了一遍,其实是感觉上面的方法有些不必要的步骤,因此自己做的时候简化了一下……
题目分析
ubuntu16 64bit 菜单题
Partial RELRO,no PIE –> 可以覆写 GOT 进行攻击
提供了四个功能:
- 添加 note,size 限制小于等于 0x80 且会被记录,note 指针会被记录。
- 展示 note 内容。
- 编辑 note 内容,其中包括覆盖已有的 note,在已有的 note 后面添加内容。
- 释放 note。
程序存在两个漏洞:
- 在添加 note 时,程序会提供写入 note 内容的功能。这里使用了一个循环且每次读取一个字符的自己写的读取函数,循环次数是 size-1 次,然而比较是无符号数比较(看来以后 for 循环里的比较符号类型也要好好注意)。所以如果 size 是 0 的话,程序就会一直读取,是一个堆溢出漏洞。
- 在编辑 note 时,程序采用及其奇怪的各种字符串操作来读取。不解释原理地简单来说,如果编辑的 note 之前 size 填入的是 0 ,而且输入的字符串大小大于 0 的话,也会触发一个堆溢出漏洞。但可惜由于出题人采用的字符串函数,这里编辑的内容遇到 NULL Byte 就停止输入了。
此外,程序最多允许申请 4 个 note,即使释放了 note 也不会增加名额。
基本思路
程序用一个全局数组对 size 和指针进行存储,因此只要用 unlink 漏洞,想办法修改那个全局数组(下称 PArray)即可。
unlink
为了触发 unlink,我们通过构造假的已释放区块来进行攻击。全局指针数组中有指向区块+0x10 的指针(因为是指向用户可用区域嘛),我们就在某个区块的可用区域构造一个假区块。
1 | newnote(0x40, b'a'*8 + pack(0x61) + pack(fake_fd) + pack(fake_bk)) # fake chunk |
首先创建一个 0x50 大小的区块(原因之后介绍),在其中构造假区块的头部。
然后再依次创建两个小区块,我们的目标是触发 unlink,就需要一个大于 fastbins 的区块大小。根据 pwndbg 调试发现该版本 libc 下 fastbins 最大大小是 0x80,因此这里的 c2 足够触发 unlink。
通过释放再申请 c1,c4 拿到了 c1 的空间,此时就可以利用那个堆溢出漏洞,修改 c2 的 chunk header,来完成假区块尾部的构造。
此时堆结构如下(使用 ASCIIFlow 绘制):
1 | │ │ │ │ |
释放 c2,将触发 free 中的 unlink,从而我们就成功地把 PArray[0]改为了 PArray-0x18。
至于 c2 之后会被 Top Chunk 吞并要不要紧,我们表示这无所谓,因为我们已经有了任意地址读写的能力了。
完成攻击
程序不仅提供了修改,还提供了展示 note 内容的功能,因此接下来做的事情可以很简单,泄露 GOT 表、覆盖 GOT 表两步。
1 | editnote(0, 1, b'a'*0x18+pack(parray+8)) # parray[0] = &parray[1] |
此时 parray[0] 指向 parray-0x18 的位置,但我们要注意 edit 功能遇到 NULL Byte 就停了,最多只能修改一个地址进去。
这里在不知道之后会遇到什么的情况下,还是稳妥一些比较好,因此这里首先把 parray[0] 设置为 &parray[1],这样我们拥有了无数次修改 parray[1] 的机会。
我们把 parray[1] 设置为 GOT[atoi],并泄露其地址,计算出 system 地址。再把 GOT[atoi] 设置为 &system。这里就发现上面不用无数次修改机会,其实 1 次就好了 hhh。
最后,由于程序每次读取菜单选项都用了 atoi (system)函数,程序本身实际上已经变成了一个 shell,只不过会多打印一个菜单出来。我们不需要输入 “/bin/sh” 只需要输入 ls 然后 cat flag 就可以拿到 flag 了。
完整 exp
1 | #!/usr/bin/python3 |
【CSAPP#0x02】程序:从源码到终止
概述
本文将从源代码开始,追溯一个简单程序从编译到运行结束的全过程。
系统环境是 WSL2 Ubuntu 20.04.5 LTS,编译使用 gcc 和 glibc 版本为 gcc (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0 以及 GLIBC 2.31-0ubuntu9.9。
使用的程序代码如下:
1 |
|
1 编译和链接
我们平时使用的”编译器”gcc,其全称是 GNU Compiler Collection,是一套组合程序,即教材中的 compiler driver。
gcc将程序编译为完整程序的过程可以分为如下几步:
- 预编译:C 预编译器 cpp 会处理源代码中的宏以及引用,并简化代码(删除所有注释,调整缩进)
- 编译:C 编译器 cc1 会将 C 代码翻译成汇编代码文本
- 汇编:汇编器 as 将根据汇编代码文本生成一个二进制的可重定位目标文件
- 链接:链接器 ld (注意加载器是
ld.so)把多个可重定位目标文件以及需要的系统目标文件进行链接,生成二进制可执行文件
在实际操作中,我们可以一步一步完成上述的整个过程。
预编译: cpp ./prog.c prog.i
编译: /usr/lib/gcc/x86_64-linux-gnu/9/cc1 ./prog.i -o prog.s
汇编: as ./prog.s -o prog.o
链接: gcc ./prog.o -o prog
最后一步还是不得不使用了 gcc,这是因为直接使用 ld 或者其封装 collect2 需要我们自己指定链接用的库,如果直接使用会报如下错误(找不到某些符号在哪):
1 | $ ld ./prog.o -o prog |
在使用 gcc 进行编译时,可以通过参数 -v, --verbose 来显示编译过程的信息。得到的信息过于复杂,但是我们也可以从中发现一部分 ld 报错的原因,在 gcc 调用 collect2 的时候,参数多得吓死人,但从中我们可以看到几个教材中出现过的熟悉的身影,这里按顺序列举一下—— Scrt1.o、crti.o、crtbeginS.o、一大堆 -L 用来指定库、crtendS.o、crtn.o 。
报错中说找不到符号_start,是因为没有链接 Scrt1.o 。报错中说找不到某些库函数,是因为没有用 -L 告诉链接器有哪些库。由于库的目录比较多,涉及到繁琐的细节,因此这里就不深究了。
我们可以检查一下每一步得到的中间文件(附件里都有),来探究一下到底每一步干了什么。
1.1 预编译
预编译之后得到一个极大无比的文本文件,与源文件相比,多出来的部分主要是两个 #include 被展开,其中包含了一大堆的函数声明。即使程序没用到这些函数,但这些函数在头文件里存在,就会被拿过来放到 .i 文件中。
1.2 编译
令人感到神奇的是,编译之后得到的汇编代码文本文件,居然只有短短的 41 行。其中有汇编代码,也有诸如 .section .string 的指令。
我们可以看到程序用到的两个常量字符串 "%15s" 和 "Hello %s\n" 位于 .rodata section,而 main 这个全局标号位于 .text 节(代码节)。
1.3 汇编
这一步能够生成目标文件,由于是二进制文件所以体积一下子变大了。
作为一个 ELF 文件,目标文件具有严格的规范,因此汇编器除了翻译 prog.s 中的指令以外,还添加了许多内容来满足 ELF 的格式。我们可以借助 objdump 和 readelf 来看看里面有哪些东西。
首先看文件头(elf header),使用指令 readelf -h ./prog.o ,其中包含了文件的魔数、架构、大端还是小端、section headers 的位置、还有各种 flag 信息。
在 section header table 中,存储了目标文件各个 section 的名字、大小、相对于文件起始处的偏移(即位置)等信息,这里结合教材观察几个重要的section。
.text节紧跟在文件头之后,有 0x48 个字节,可以用objdump -d反汇编程序所有可执行代码;.rel.text节记录了需要重定位的代码地址;.data节和.bss节分别存储已初始化和未初始化的全局变量,这里大小都为 0;.rodata节存储只读的常量,大小为 0xf,恰好是两个常量字符串大小相加,十分合理;.symtab节记录了函数和全局变量的信息 (readelf -s),比如main和用到的库函数(UND);.strtab节记录了符号表中符号的名称 (readelf -p .strtab),比如 “main” 和 “malloc”。
1.4 链接
链接过后的 目标文件成为了可执行文件,体积一下子从 1.7K 变成了 17K。
首先是多了一个端头部表,或者称为 PHT(Program Header Table),用来指示加载器如何加载各个 segment 到不同的页中(包括各个 segment 的物理和虚拟地址、物理和虚拟大小等信息)。
其次是多了许多的代码,重要的如 _start,处理动态链接的 .plt segment,_init 和 _fini。
此外还添加了许多数据结构,重要的如记录库函数真实地址的 GOT 表,记录动态链接所需信息的 .dynamic 节,本报告后续会提到这些数据结构。
2 命令行执行
终于到了激动人心的执行时刻。这一部分将会探索从命令行执行指令 ./prog,按下回车键,一直到程序开始执行 _start 中的第一条指令前,计算机都完成了哪些工作。
首先,shell 程序会对指令进行解析,把字符串拆分成一个字符数组,这里就是单纯的一个 ["./prog", NULL]。
在 shell 确认这不是一个内置的指令后,它会 fork(系统调用)出一个子进程,内核为新的子进程创建其数据结构、分配一个新的 PID 、并复制一个 mm_struct 然后把里面的页都标记成 private copy-on-write,从抽象上讲已经为新进程复制了所有的空间。
由于我们没有用 '&' 指定后台运行,因此 shell 主进程会调用 waitpid 系统调用来等待子进程运行结束。
而对于子进程,通过 strace 工具可以明确看到,接下来它会调用 execve("./prog", ["./prog"], 0x7ffea1185a30) = 0,来让自己”变成”我们运行的程序,或者说 .prog 替换了 shell 的子进程的程序。其中,0x7ffea1185a30 是环境变量数组的地址, shell 会直接让子进程继承自己的环境变量。
结合 execve 的 man page 和教材,execve(即内核)会负责完成程序的加载:删除原有用户空间的地址映射,然后重新映射新程序的代码段、数据段、栈的区域。如果程序是动态链接 ELF 的话,内核还会调用 PT_INTERP segment 中记录的动态加载器。使用 glibc 编译的话就是 ld.so。
由于是内核处理,因此 strace 不会记录这些过程。
可以用 ldd 工具查看+查找一个 ELF 需要的动态链接库和动态加载器。我们看到程序要求的加载器为 /lib64/ld-linux-x86-64.so.2。
1 | $ ldd ./prog |
另外,由于按需加载原则,实际上这里并没有将程序真的从硬盘中取到内存中,而只是在页表中添加了其映射关系。
我们借助 strace 工具以及进程的 /proc/[PID]/maps 来分析这个过程。
首先子进程会调用 execve,在执行完 execve 后出现了一大堆系统调用,是加载器 ld.so 加载共享链接库的过程。(通过共享库的加载地址和 strace 打印的 mmap 返回地址对照即可发现)另外,加载器 ld.so 本身的加载由 execve (也就是内核)完成,因为我们在 execve 之后并不能看到加载加载器的系统调用。
在动态加载器操作完之后,共享库映射关系都已经确定(或者说已经 allocated 了),此时才会真正开始从程序的入口处执行程序。为了证实这一点,我们可以通过 gdb 下断点断在 _start 处,然后查看此时程序的虚拟地址空间映射(这里使用了 gdb 插件 pwndbg 提供的 vmmap 指令),可以看到这时共享库确实已经被加载完毕了。
之后,终于进入程序运行流,开始运行程序。
3 启动 main 函数
本部分我们来简单探索一下从 _start 到 main 的过程。由于这部分教材中并没有详细讲解,因此本报告中也不深挖这部分的细节。
简而言之,_start 调用 __libc_start_main,顾名思义是位于共享库 libc 中的一个用来启动 main 函数的函数,其实同时也负责在 main 函数返回后处理程序后事。
然后 __libc_start_main 会调用 main 函数,进入程序员编写的代码部分。
我们可以通过 gdb 来观察这个过程,只需要从 _start 一步一步执行即可。逃课的方法就是把断点下在 main,然后使用 backtrace 查看这时的函数调用关系:
1 | pwndbg> backtrace |
更具体一些的话,__libc_start_main() 会调用程序静态链接的 __libc_csu_init() 函数,这个函数又会调用位于 .init 段中的 _init_proc() 和位于 .init_array 中的函数。(这是一个函数指针数组)
此外,__libc_start_main() 还会调用 _cxa_atexit(),这个函数可以让库函数 exit() 在退出程序前执行指定的函数,这里是让 exit() 执行 __libc_csu_fini() 函数。
在进行完上述步骤后,它才会调用 main 函数,真是十分复杂的初始化过程。报告写得如此详细,是因为我接触过一道通过修改与 .init_array 类似的 .fini_array 中函数指针的地址来完成攻击的 CTF 题目(pwnable. tw-3x17)(这两个全局变量竟然是 RW 的)。
本部分参考了 linux编程之main()函数启动过程。
4 运行 main 函数
进入 main 函数的执行!main 函数作为一个用到了局部变量的用户态函数,会在用户栈中有属于自己的栈帧,因此在函数的开头和末尾都有用于开辟、退出栈帧的代码。
在我们的程序中,main 调用了三个库函数—— malloc(), scanf() 以及 printf()。在调用它们之前,main 函数会将参数放到 rdi 和 rsi 等寄存器中(在汇编指令中可能会放到 edi 等寄存器中,由于高 32 位会自动清零,这么做可以缩短代码长度),这是 64 位 Linux 的规约。在 32 位 Linux 下就不会这么传参,而是将参数按顺序放在栈上(第一个参数在地址最低处,以此类推),然后再调用函数(因此返回地址上面就是其参数)。
之后本章将会分为三个小节——动态链接、动态内存分配和 I/O。
4.1 动态链接
动态链接库 libc.so.6 在被加载到内存时,由于 Linux 系统默认开启的 ASLR 保护,它会被加载到一个随机的位置,不过仍然满足基础的 4KB 的页对齐(也就是其基址最低 12 比特一定是 0)。程序需要调用的库函数,其实际位置(指位于进程虚拟内存空间的地址)在加载器 ld 用 mmap 把共享库映射到进程的虚拟内存空间之前是未知的,因此在程序开始运行后我们需要处理动态链接的”重定位”。
之所以这里重定位打了个引号,是因为动态链接的符号,其重定位机制和静态链接大有不同。静态链接的重定位就是直接修改代码中的地址,但动态链接不是这么处理的。
理由之一是进程的代码段权限是 RX,也就是不可写的,要是可写的话会产生严重的安全隐患。但对于这个理由我可以提出疑惑:如果让 ld 在程序的 _start 开始执行之前,就由 ld 做好全部代码的重定位,然后再用 mprotect 系统调用修改代码段权限为不可写,不是一样安全吗?
但是问题来了,这样对大量引用库函数的程序非常不友好:在程序还未开始时,ld 会花较大的时间开销来进行重定位工作,这时的重定位可不像编译软件时一样慢点也就慢点了,而是会实实在在地增加程序运行的启动时间。
因此,类似于按需调页的机制,动态链接也使用了延迟绑定(Lazy Binding)的机制,只在用到库函数的时候才去处理它的重定位。显然,上述修改代码段的地址引用的重定位方法无法做到安全的延迟绑定,因此有了 PLT 和 GOT 表机制。
简而言之,GOT(Global Offset Table)存符号地址,PLT 存负责调用 GOT 的代码。
回到我们的 prog,当它调用库函数时,它实际调用的是 PLT 中的代码,可以用 objdump 看到:call 1040 <malloc@plt>call 1050 <__isoc99_scanf@plt>call 1030 <printf@plt>
以 malloc 为例说明延迟绑定机制,注意到我的环境下编译得到的 PLT 和 GOT 机制与教材中有差异,但本质不变。
当 prog 第一次调用 malloc 时,GOT 中还没有其实际位置,而是保存着 PLT 中某处的代码地址。所以第一次调用 malloc 的大致流程如下,我们使用 gdb 追踪一下这个流程 :
调用
malloc对应 PLT 条目代码,并跳转到 GOT 当前记载的地址0x0000555555555040:1
2
3
4
50x555555555080 <malloc@plt> endbr64
► 0x555555555084 <malloc@plt+4> bnd jmp qword ptr [rip + 0x2f95]
pwndbg> x/gx $rip+0x2f95+0x7 # 加的0x7是该指令本身长度
0x555555558020 <malloc@got.plt>: 0x0000555555555040虽然
0x0000555555555040不像书中一样是malloc@plt的第二条指令,但其工作和书中相同:将malloc对应编号压栈并调用 PLT[0]:1
2
3► 0x555555555040 endbr64
0x555555555044 push 1
0x555555555049 bnd jmp 0x555555555020PLT[0]将 GOT[1]压栈并调用 GOT[2],也就是负责处理动态链接的
ld.so中的库函数_dl_runtime_resolve_xsavec ()。1
20x555555555020 push qword ptr [rip + 0x2fe2] <_GLOBAL_OFFSET_TABLE_+8>
► 0x555555555026 bnd jmp qword ptr [rip + 0x2fe3] <_dl_runtime_resolve_xsavec>动态链接器将 GOT[“malloc”]覆写成其实际地址,并直接调用之。此详细过程严重超纲因此不在本报告研究范围内。在从
malloc返回之后,我们用 pwndbg 的命令got查看当前 GOT 表,可以看到只有malloc地址被填好了,还没用到的printf和scanf都指向 PLT 某处:1
2
3
4
5pwndbg> got
GOT protection: Partial RELRO | GOT functions: 3
[0x555555558018] printf@GLIBC_2.2.5 -> 0x555555555030 ◂— endbr64
[0x555555558020] malloc@GLIBC_2.2.5 -> 0x7ffff7e660e0 (malloc) ◂— endbr64
[0x555555558028] __isoc99_scanf@GLIBC_2.7 -> 0x555555555050 ◂— endbr64
另外,值得一提的是 Linux 的 RELRO 保护机制。
开启了 Full RELRO 保护的 binary 会在 main 开始运行前就将所有的 GOT 表项填充完毕,程序执行时 GOT 表权限不可写,从而防止攻击者覆写 GOT 来劫持程序控制流。
不知为何,我的环境下使用 gcc ./prog.c -o prog 编译出的可执行文件默认开启了 Full RELRO 而非采用延迟绑定的 Partial RELRO,因此为了开启延迟绑定,需要添加编译选项 -z lazy。上面的分析就是我开启了延迟绑定之后重新编译后完成的。
4.2 动态内存分配
动态内存分配的过程其实可以拆分成多层,我们关注三层:
- 用户程序 prog,调用
malloc函数 - 库函数
malloc,负责调用系统调用brk和mmap - 系统调用
brk和mmap(内核代码)负责处理虚拟页分配的工作
本节重点关注中间那层——malloc可以看作一个对brk和mmap的封装,在内核给的大块空间的基础上,根据用户需求切割成一个个小的 chunk 给用户使用,为了增加 locality 而编写了一套十分复杂的已释放区块复用&回收的机制。
由于我们的 prog 没有多线程,因此他的堆是通过 brk 来分配的。我们通过 strace 输出和 gdb 来尝试观察。在 gdb 中使用指令 catch syscall brk 可以捕捉 brk 系统调用,我们第一次捕捉到是在运行 ld.so 中的代码时,对应 strace 开头捕捉到的一次。第二次就是运行 malloc
时了,所以 malloc 实际调用了两次 brk :
1 | brk(NULL) = 0x563917de6000 |
第一次调用是为了获取当前堆顶指针的位置(虽然这时候堆还不存在),第二次获取是为了设置堆顶指针的值,也就是给堆申请了空间,简单计算得出申请大小为 0x21000,也就是 33 个页(132KB)。
在得到这么大一片空间后,malloc 会从其中分出一小部分来给用户。我们使用 pwndbg 来查看从 malloc 返回后堆的区块情况:
1 | pwndbg> heap |
- 地址最低处的 0x290 大小的区块和一种释放区块缓存机制 Tcache 有关,这里不细究。
- 中间的那个区块就是用户程序申请得到的空间,0x21 中那个 1 是一个 flag,表示前一个区块正在使用中(PREV_INUSE bit),0x20 而不是 0x10 是因为这个 chunk 的前 0x10 字节用来存储一些 metadata(具体来说是 prev_size 和 size 字段),后面的 0x10 是真正给用户使用的空间。因此,
malloc的返回地址也不是这里显示的 chunk 地址,而是加了 0x10 后的地址。 - 最后一个是特殊的 Top chunk,
malloc用这个超大的 chunk 来指代没被分配给用户的空间
我们在调用 scanf 并输入 "aaaabbbbccccdddd" 后再来看看这个 chunk 的内容:
1 | pwndbg> x/4gx 0x555555559290 |
这就证实了上面介绍的 chunk 的结构。我们调用 scanf 时限制读取 15 大小,因此这里用户可用的 0x10 个字节最后正好用来存放 NULL Byte,没有出现溢出。由于小端法,这个地址最高位的 '\x00' 被理解为一个八字节整形的最高位。
4.3 I/O
IO 相关库函数和 malloc 一样,是封装了系统调用 read 和 write 并提供更复杂接口功能的函数。scanf 和 printf 会使用从 shell 那里继承下来的文件描述符 stdin 和 stdout 来读取和输出。
IO 相关库函数会有自己的 buffer,而非直接进行输入输出。在调用了 scanf 后,我们再在 pwndbg 里使用 heap 指令,就可以发现 scanf 调用 malloc 分配了一块大小为 0x411(申请大小为 0x400)的空间,这就是输入的 buffer;在 printf 结束后同样可以看到一块输出的 buffer。(我们甚至还可以检查一下 Buffer 里的内容,但报告已经满 8 页就不看了)
1 | Allocated chunk | PREV_INUSE |
5 程序退出
当 main 函数返回后,程序回到 __libc_start_main,然后调用了库函数 exit。库函数 exit 会调用系统调用 exit。内核具体干了什么超出了 ICS 的教学范围,这里我们就快进到进程已终止。
如果不被父进程回收的话,那么这个程序会一直保持僵尸状态;不过我们运气很好,shell 主进程还一直 waitpid 着呢。于是 shell 把它的子进程回收了,在命令行上打印出一个 prompt,然后继续等待用户输入下一个指令。至此,程序运行完成!
【Pwn#0x08】0CTF 2017 babyheap
放寒假了,于是我把ptmalloc2机制又重新学习了一遍,开始做点简单的堆利用题了!本题一半抄一半自己摸,也算是基本搞懂了,这里放一个笔记。
基础信息:
ubuntu16(glibc2.23),菜单题,64 位,保护全开。
提供 alloc、 free、dump、fill 功能,同时允许分配 16 个区块。
漏洞:
fill 功能可以向区块写入任意长度信息,也就是堆溢出。
由于保护全开,于是 pwn 的目标便是:
- 泄露 libc 地址
- 修改__malloc_hook 为 libc 中的 one gadget
泄露 libc 地址
ubuntu16 下没有 tcache 机制,因此只有 fast bins 和 3 个普通的 bins。其中,fast bins 以单链表形式维护,非循环链表,因此无法泄露 main_arena 的 malloc_struct 地址。而普通 bins 都是循环链表,large bins 比较复杂,但 unsorted bins 和 small bins 中的 chunk 都会有指向 arena 的指针。
我们需要泄露这个指针,就需要想办法构造 UAF 或者 overlap。如果构造 UAF 的话,就需要使两个指针同时指向一个区块,然后 free 其中一个,这可以通过 poisoning the fastbin 做到(修改 fastbin 链表为某个特定区块,然后就可以把这个区块分配出来)。
1 | # --- leak libc base --- |
为了给 fastbin 下毒,我们需要链表中有两个区块,然后利用堆溢出修改其 fd 指针到想要的区块。因此首先就分配 4 个区块,编号 0 的区块用来溢出区块 1 的信息,编号 3 的区块用来防止合并,编号 1 和 2 待会会被释放,且顺序为先 2 后 1,理由是这样 1 区块就会因为前插法位于链表的头部,这样就方便用编号 0 的区块来溢出它,但实际上由于溢出大小无限制,想怎么溢出都可以。
此外,我们还需要一个会被扔到 unsorted bin 的区块,fastbin 在 64 位下允许最大的大小是 0xb0(包括 chunk 头),所以我们这里就申请一块 0xb0 大小的空间(对应 chunk 大小 0xc0)。我们待会要释放它,为了防止它和 top chunk 合并触发 consolidation,我们再分配一个区块用来占位。
1 | free(2) |
然后我们将区块 1 和 2 释放,他们会被放到 fastbin 的一个链表中。
我们从区块 0 开始溢出区块 1 的 fd 指针,将其最低 bit 修改为 0x80。这里利用了虚拟页大小为 0x1000 的特性,区块的后 12bits 不变,因此 0x80 处就是区块 4。
我们还需要将区块 4 的大小改为 0x21,这是为了通过 fastbin 分配区块的检查。
1 | alloc(0x10) # 1 |
然后我们此时分配两个区块,程序会顺位编号(类似 fd 的分配),所以分配得到的区块会被编号为 1 和 2。此时,区块 2 就是区块 4!我们已经做到了让两个指针同时指向一个区块。
1 | # change 4's size to 0xc0 (free check) |
接下来我们 free 其中一个指针。为了通过 free 的检查,我们再用溢出将其大小改回其真实大小 0xc1。(具体来说,如果不改的话,该 chunk 属于 fastbin,free 会检查该 chunk 物理高位的下一个区块的大小是否正常,然后会惊喜地读到一个 0,并报错。)
在将其释放之后,它不属于 fastbin 且没有可以合并的区块,于是被放进了 unsorted bin。这时我们就可以 dump 区块 2 来查看 unsorted bin 的地址了(实际上是 bins 的地址,因为 unsorted bin 作为一个 malloc_chunk,其位置是 &bin[0],其 fd 字段位置才是 &bin[2])。
覆写 __malloc_hook
为了覆写__malloc_hook(地址已知),我们需要寻找其附近的现存 fake chunk。我觉得这应该有工具可以做到,我只找到了 pwndbg 提供的 find_fake_fast 指令,但我这次没有成功,它给我报错(呜呜呜)。
然后询问了学长,得知一般是 &__malloc_hook 减去 0x23 或 0x33 之类的位置,因为 0x7f 是一个合法的 size(我猜是因为有了 IS_MMAPED bit,别的 bit 都会作废)。使用 pwndbg 的 malloc_chunk 指令查看这两处,发现 size 字段确实是 0x7f。
那么接下来就很简单了,我们分配两个大小为 0x70 的 chunk,把它们释放进 fastbins,然后堆溢出把 fd 改成 fake chunk 的地址(和上面流程一样)。
最后用 fill 把 __malloc_hook 改了,再随便 alloc 一下,成功用 one gadget 拿到 shell!
完整 exp
1 | #!/usr/bin/python3 |
【杂谈#0x04】
最近发生了很多事情,但我也总结不出什么道理,所以就写个杂谈来分享下我看到的事情和我的感受吧。
第一是疫情防控的急速转变。
从乌鲁木齐市的大火开始,网上就有一股强大的反抗当前防疫政策的力量出现了。那段时间是我朋友圈里,不存在的文章占比最高的一段时间。甚至不仅仅是网上,在现实中也有许多人开始抗议,以举白纸的方式。
这很显然是多个因素推动造成的,其中不乏境外势力的推动。但是不论因素是什么,民众中已经形成一股怨气了。
可想而知,不论多么小心,未来一定会有类似乌鲁木齐大火一样的惨剧发生,这是中国作为一个大国所无法避免的,这里的大说的是规模、人口、差异之大。而网络的存在又消除了信息的传播限制,使得全国都能获取到事件的相关信息,使这股怨气仿佛滚雪球一般越传越大。
因此在这种情况下,选择放开是十分合理的措施,并且一定要放开到让老百姓意识到明显不同的程度。
所以现在大的真的来了:
pafd。出校刷卡。线上。提前。推迟。后续安排问卷。活动取消。离校。抢票。见证历史。一时间所有的东西都转了起来。
第二是不可抗力带来的迷茫。
在这周三四五,我每天都遭受了一次课业上的打击。周三错过了一学期只点名一次的毛概点名;周四在集合与图论的单元小测中失利;周五基物实验成绩公布,绩点排名又降了。
这让我不得不反思我已经思考过好多次的东西:培养方案,绩点与保研制度,以及意义问题,我到底想要什么,为了我想要的东西,这些课内的东西是否是重要的?
社会的主流价值观是一股洪流,每个人都在其中无法彻底挣脱。然而,从现实世界的客观的主流的意义标尺,转化为我们心中的意义标尺,中间还有一个关键的步骤,就是我们发自内心的对其真正的领会和认同。
我不认同这套评价体系,这种体系能起到区分作用,能筛选出厉害的人,但许多为了在体系中取得高分的努力,一旦出了这个体系就毫无意义。
引用我的俩朋友说的话:“不按培养方案选课也是一种对自己负责”(来自数院),绩点是“足够就行了”(来自微电)。
但是上面这些只是非常基础和显然的东西。真正令我难以摆脱体系的问题是,在抛弃了那些无意义的任务之后,我应该干什么?换句话说,从被动(学习)转换为主动(学习),学什么呢?
我有过许多答案,这些答案没有正确与否,具有很大的自由性,但问题也出在这里——我无法确信我的答案就是正确的。对于我这样生活经历普普通通毫无波澜的人来说,形成一个自己能够坚信的意志需要时间、经历、正反馈来培养,是非常困难的。
尤其是正反馈,若想要得到多数人(也就是主流)的认可,必须做主流的事才行。否则就是非主流,就只能得到相对少的认可和理解。而当在主流的体系中遭到挫败,就非常容易产生自我怀疑、对应该干什么的迷茫。
未来的我,你会找到能够坚持下去的梦吗?你能找到心灵的归宿吗?
【Pwn#0x07】THUCTF 2022 babystack_level3
比赛链接:THUCTF2022
(报名了比赛的账号现在(2022/11/15)还可以下载附件和开启实例)
学习了一下ret2dlresolve的基础。
在NO RELRO的时候,程序的.dynamic节被存储在RW的地址空间,而其中的一个指针strtab指向的是动态链接的符号表。
我们可以把这个符号表提取出来,修改一下,存在一个别的地方,然后把.dynamic里面的指针修改到那个地方。然后程序就会使用我们的假字符串表来进行动态符号解析!
题目分析

整个程序,一个输出函数都没有,但是保护只开了NX。很显然是要用ret2dlresolve来做。(实际上做题目的时候我还没学ret2dlresolve,然后去网上搜没有输出函数怎么打搜到的哈哈哈)
漏洞是可以在一个固定地址读入0x110个字节,并且可以栈溢出0x10个字节,也就是刚好把返回地址给覆盖掉。
那么思路就是
- 把rop chain读到固定地址那里,然后stack pivot过去
- rop chain是构造一个假的dynstr表(比如把read改成system),然后把.dynamic那里的指针改成假的dynstr,并且跳转到plt来触发动态符号解析,来调用想要的函数。
大失败原因
这题我本地打通之后,花了整整两天才在在线环境上打通,并且主要是靠出题人dylanyang师傅超级善良好心的debug帮助。
我们知道,栈地址是向下增长的,因此之前调用过的函数,其栈帧会被新的函数给覆盖,或者说重用。
在ROP中也是这个道理,虽然ROP链是按照调用顺序向上增长的,然而如果调用的是函数,函数的栈帧将会向下把一些东西给覆盖掉。
而我是如何踩进这个坑的呢?
在经典的stack pivot中,新的ROP Chain的第一个8字是会被当作saved rbp来pop给rbp的,所以是无用的一个八字。(如果你不想第二次stack pivot了)
然后我是一个非常懒惰的人,当我发现”/bin/sh\x00”正好是八个字节的时候,我心动了。把这八个字节填到新ROP Chain的开头不是正正好好吗!?
然后就寄了!因为在调用后续函数如execv、do_system的时候,栈帧会往下增长并且把这八个字节给覆盖掉!
以下是调试的截图,可以看到在执行完posix_spawnattr_init之后,我提前存在这边的”ABCDEFGH”突然变成了0……
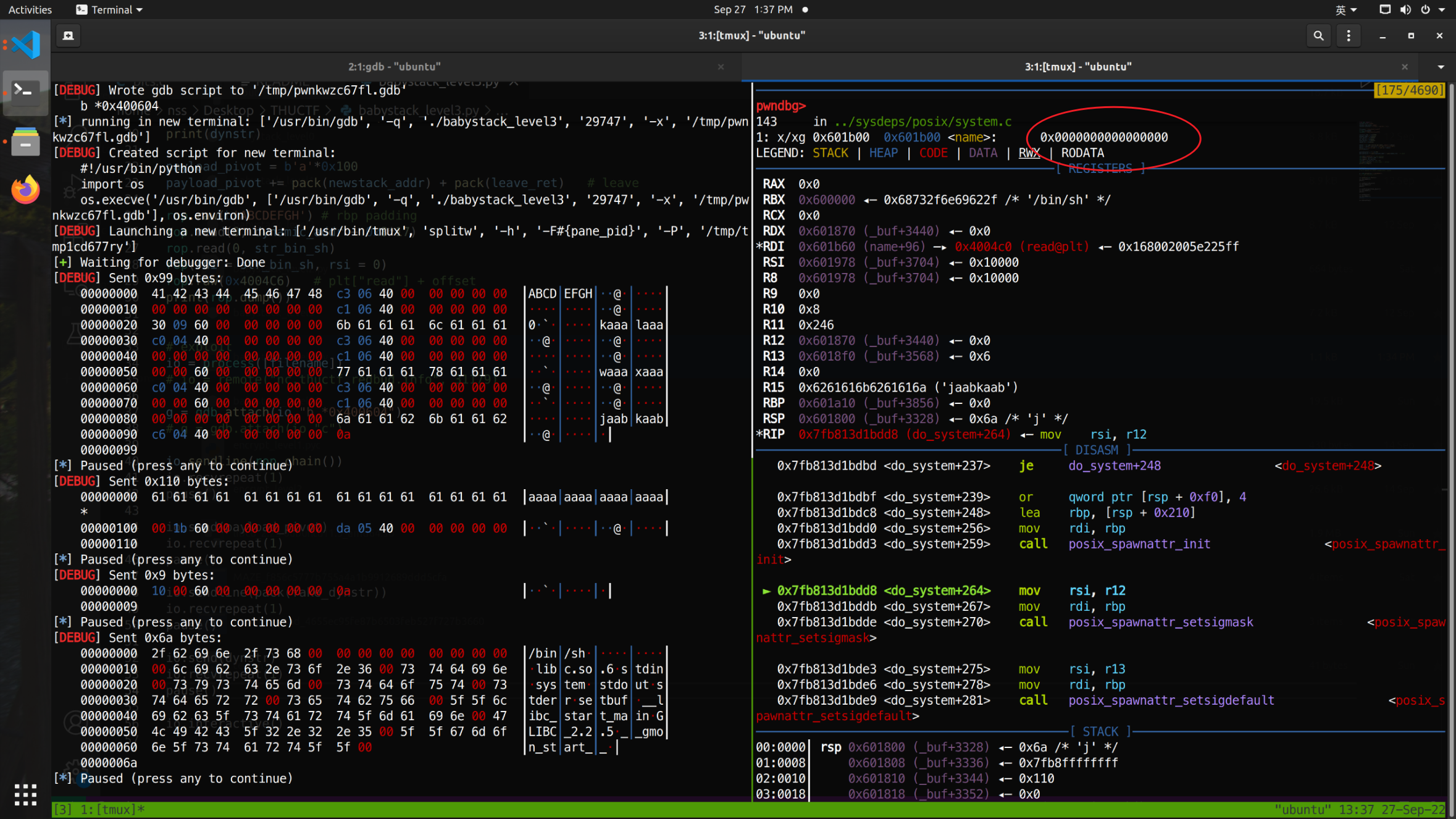
解决方法实在是很简单,换一个位置存”/bin/sh”字符串就行。
但是不知道这个问题的话,自己来调试实在是看不出什么东西。真的是我遇到最奇怪的情况了……
EXP
1 | from pwn import * |
【杂谈#0x03】
昨天,一个好朋友在空间转发了一篇介绍中文系究竟能让学生学会些什么的文章。
文章一开篇就提出:
我经常劝年轻人(虽然我也是年轻人= =)少去“解构”,学会能帮助你写出一篇还不错的批评文章,但学会解构之后,你常常不可抑制地会去解构身边的一切,然后觉得一切都不值得你去作为理想奔赴。
给出两个定义:
把那些堂皇的、巨大的存在拆解开来,就是解构。
世界上一切的意义、巨大堂皇的存在,都是建构。
然后这一过程,非常巧合地,在当天晚上就在我没有意识到的情况下发生了……
今天早上看数据结构的时候才突然意识过来(为什么是在看数据结构的时候意识过来,可能只是我不想看这么厚的教材所以故意找点小差来开)……
事情是这样的。由于我和母上聊天时,发现她居然不知道现在的首富是马斯克,所以晚上在b站上找了期介绍马斯克的视频来一起看。
于是我找到了我非常喜欢的up——电丸科技AK——的一期视频 埃隆马斯克 Elon Musk可能不是救世主 但他一定是个孩子。
看完后我受到了极大的震撼,很难想象马斯克是如何坚持他的目标的。这和我预想的对于“首富”这个词的刻板印象完全不同,感觉他就是本世代的“主角”了……
然后我看完之后又去知乎搜了搜,想找到更多对他的评价和对他过去行动的解读。不过没找到,但是找到了好多别的东西,比如马斯克的桶装胸,对马斯克自称每日工作17小时的评价,马斯克只是画饼,马斯克背后都是财团等等。这些人也说得有点道理,但这样一来,那些原本宏大的目标似乎就不再宏大。
如果移民火星、脑机接口、火箭、卫星以及新能源都不能成为激励人的梦想的话,那么还有什么梦想能激励一个工程师呢?
去解构马斯克的目标是有代价的,代价就是我自己的相比之下十分微不足道的小梦想被轻易地一并解构了,然后又回到了我的老朋友虚无主义。
所以,不管马斯克结局如何,手段如何,真实目的如何(阴谋论老多了),我还是会尊敬他。因为他是一个不一样的首富,是一个开辟新赛道让长期只存在于学术界和科幻故事之中的领域进入大众视野的人。
我会看着他去实现他的目标,并一步步实现我的小梦想。