暑假写的中缀表达式和后缀表达式的转换程序只支持个位数加减法,实在是太菜了。
所以我参考教材上的方法(教材给的代码也只支持个位数加减法,实在是太菜了),把它升级了一下,写了一个 (中缀表达式)计算器。
【Pwn#0x04】BUUCTF get_started_3dsctf_2016
十分诡异的情况:本地打得通,远程打不通并提示timeout: the monitored command dumped core。
【杂谈#0x00】
关于教育和学习的一些想法(黑历史,但留着吧hhh)
【Pwn#0x06】pwnable.tw applestore writeup
把局部变量用作静态变量,是不是一种栈上数据的UAF……
【Pwn#0x05】pwnable.tw hacknote writeup
UAF,以及发现了使用system()的小技巧。
【pwn.college#0x03】babyheap writeup
Here's something encrypted, password is required to continue reading.
【Pwn#0x03】pwnable.tw silver_bullet writeup
Off-by-NULL
【Pwn#0x02】pwnable.tw dubblesort writeup
【Pwn#0x01】pwnable.tw 3x17 writeup
好难的一关,顺着这关学了好多东西……
Part0 符号名呢
摸索
本题是一个strip后的静态链接文件……
当我打开IDA,我看不到任何一个函数名,只有一大堆地址迎接我。
于是我在libc里耗了一天,成果只是大致知道执行了哪些函数,并且给read、write库函数标了名称。
然后我想了一个方法,我是不是可以根据函数的地址来看出这是哪一个libc版本,然后就可以给每个函数都标上名称了?然而不行。
静态链接不像动态链接,它只把用到了的函数链接进文件,因此库函数的地址和它在库中的位置毫无关系。
然后当天晚上做梦的时候,我梦到真的有这么一个库,我一把库拖进IDA PRO,软件自动给所有的函数都标上了名字。
醒来的时候我一想,会不会真有根据函数特征来识别函数名的功能?拿起枕边手机一查就查到了。(话说你不能早点查吗)
解决
参考利用ida pro的flare功能识别静态链接函数签名_Anciety的博客
IDA支持给特定库生成一个签名,然后用这个签名识别库函数的名称!
有人已经生成过很多签名了,可以直接去push0ebp/sig-database: IDA FLIRT Signature Database (github.com)下载。
那么问题来了,下哪个libc版本呢?
pwnable.tw的官网首页说,题目都运行在ubuntu16.04或18.04上,所以我先去把这两个系统对应的libc都下了下来,发现只识别了五十几个库函数……
然后又下了一大堆libc版本,最后在19.04里找到的libc6_2.28成功匹配到了六百多个库函数。
于是我终于知道哪个是main函数了……然后发现离成功还尚早……
Part1 分析(放弃)
本关开启了NX和Canary,没开PIE,那么应该是可以修改某些东西的。
main函数干了四件事:
- write一个”addr:”
- read一个0x18长度的字符串,并用一个库函数将其转换成数字(当成10进制数)。
- write一个”data:”
- read一个0x18长度的字符串,地址是刚刚输入的数。
然后就ret了。可以发现,我们没有任何泄露栈地址的方法,没办法进行简单的ret2xxx系列攻击。
(然后我就放弃了,这题大概又是超出我知识水平范围的,所以去网上找writeup:和媳妇一起学Pwn 之 3x17 | Clang裁缝店看了)
Part2 main函数的启动过程
参考教程:linux编程之main()函数启动过程_gary_ygl的博客
读了文章,学到很多姿势,尤其是对于C程序的抽象->具象:
从一开始的程序运行过程就是main开始到结束;
到后来知道从start开始,start负责调用__libc_start_main(),__libc_start_main()再调用main()函数;
再到现在发现__libc_start_main()干了很多事情,包括在调用main()函数之前,调用__libc_csu_init()函数,并且用_cxa_atexit()函数设置程序退出前执行__libc_csu_fini()函数(具体来说exit()调用_run_exit_handlers(),并在其中按照倒序调用之前用_cxa_atexit()注册过的函数)。并且在调用main()之后,会调用exit()函数。
(其实还干了一些初始化以及善后工作,但是和链接比较相关,和本题不那么相关)
而逆向本题可以看到,__libc_csu_init()主要做两件事:
- 调用位于.init段中的_init_proc()
- 按顺序调用位于.init_array中的函数(这是一个函数指针数组)(数组大小固定,汇编中直接用立即数地址计算数组大小)
类似地,__libc_csu_fini()也干两件事,但是和init是正好顺序相反的:
- 按逆序调用位于.fini_array中的函数(这是一个函数指针数组)(数组大小固定,汇编中直接用立即数地址计算数组大小)
- 调用位于.fini段中的term_proc()
然后画个图表示一下我的理解:
而.init_array和.fini_array都是rw的,可写!
然后我决定在懂得了这些之后再自己尝试一下利用!
Part3 Exploitation
通过覆写一次fini_array,可以达到如图的效果。
由于不存在wx的段,所以放弃shellcode,想想如何ROP。
光凭fini_array这两个call是没有用的,必须想办法stack pivot一下。
刚开始的思路是利用
1 | 0x00418820: mov rax, qword [0x00000000004B7120] ; ret ; |
这两个gadget来把rsp弄到我想要的地方。但是我发现这做不到,原因是fini_array只有两个元素,我不论怎么修改这个数组,都只能实际调用一个gadget。
原因如下: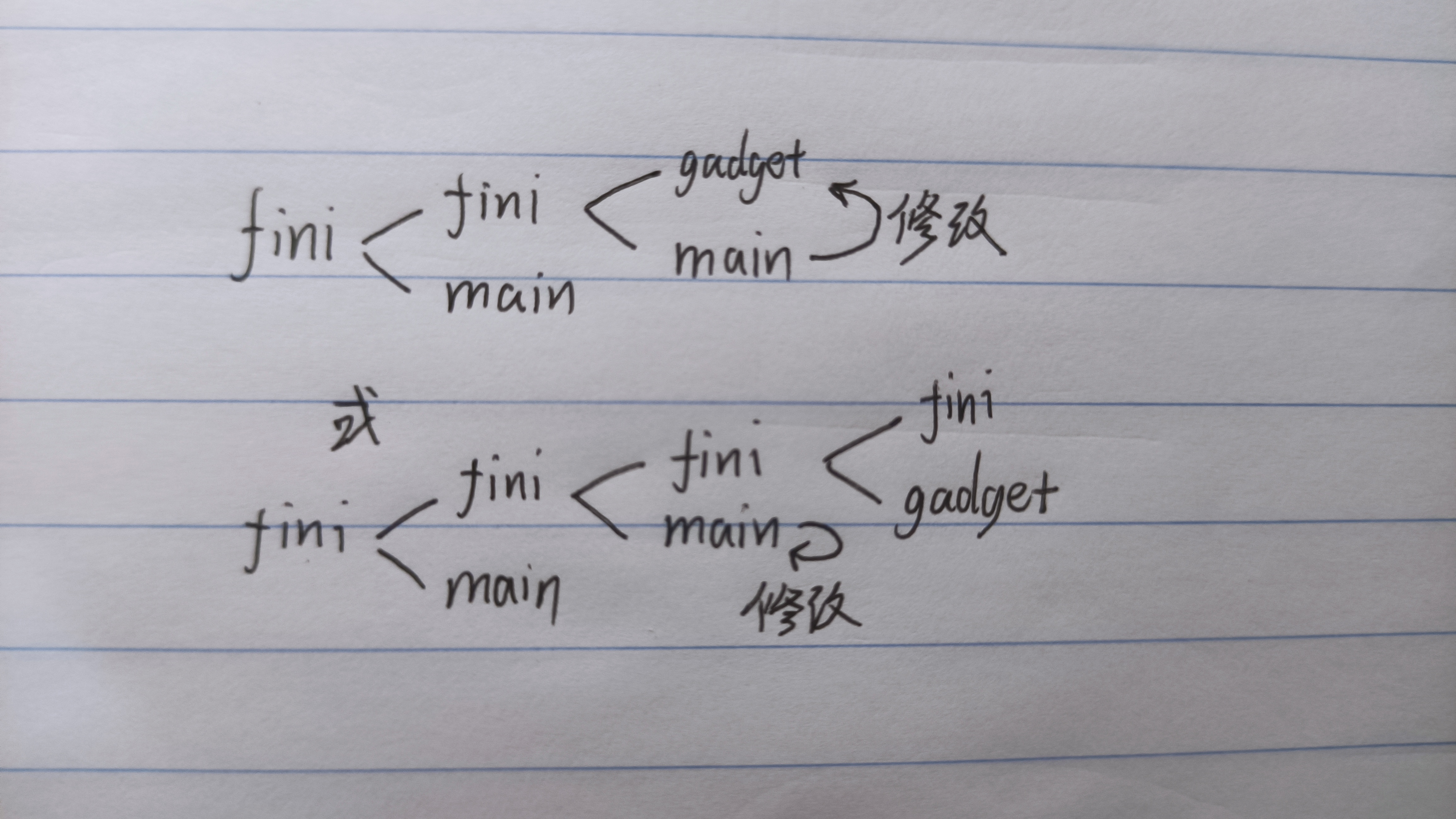
我们必须要用一个gadget完成stack pivot,这意味着要么有一个gadget同时涵盖了赋值+修改rsp的工作,要么利用寄存器或栈上已有的值。
GDB动态调试到这里,发现确实有几个寄存器存着RW的位置,其中就包括rbp。然后回忆一下:leave = mov rsp, rbp; pop rbp; ,用这个来stack pivot。
然后利用静态链接程序的丰富gadget库轻松写出了ROP chain,拿到了shell。
1 | from pwn import * |
一个小技巧:
如果不间断地给程序send数据,很可能send到同一个read()里。
面对这种情况,可以在两个send()中间recv()一下,又或者加上一个pause()手动停止,又或者加上一个sleep(0.15)来自动停止。
【Pwn#0x00】pwnable.tw-start/orw/calc writeup
start
是我太年轻了,第一题做了一小时半才拿到flag……
首先一看,保护全关的32位程序。
1 | $ objdump -d -M Intel ./start |
有3个syscall,一个write把一个字符串写到1,一个read从0读入字符到栈上,一个exit退出。显然read这边有个栈溢出漏洞,可以把返回地址覆盖掉。
首先想到直接在返回地址后面写一段shellcode执行execve(“/bin/sh”, 0, 0),想盲打打中栈地址。但是试了几次发现即使是32位的程序,也有至少19个二进制位的随机变化,要十几个小时才能打中,于是算了。
然后想ROP试试,但是怎么想也想不出方法。
最后想到重新执行的思想,我可以重新执行write和read,把栈上的栈地址(嗯?)泄露出来,这样就可以把控制流精准控制成我的shellcode了。
然后终于做出来了,你说我怎么老是最后才想到重新执行这种方法……
1 | from pwn import * |
orw
程序会读入一段shellcode并执行,并且限制syscall只能调用orw。
先用read读入/home/orw/flag,然后orw就好了。
1 | from pwn import * |
calc
除了PIE,其他保护全开。
是一个计算器,将读入的表达式转换成逆波兰表达法之后,用栈进行求值。
主要漏洞在于,在利用栈进行求值的时候,这个存数字的栈用[0]存储栈的高度,用[1]及以上空间存储数字。
所以当我输入 +1 的时候,这个1将会直接被加到栈的高度上,之后就可以通过修改栈高度+构造表达式。来达成栈以上地址任意读写(实际只用到了任意写)。
遇到了两个坑,一是写入一个数字的时候,比这个数字低位的数字将会受到影响;二是运算数不能为0。
前者利用倒过来写入(从上往下写)解决,后者我利用构造表达式解决(后来发现了更简单的方法,由于是将运算数与”0”进行strcmp来判断的,我可以输入000来表示0)。
1 | from pwn import * |